Kafka原理探究
Kafka索引
Kafka的索引是稀疏索引,这样可以避免索引文件占用过多的内存,从而可以在内存中保存更多的
索引。对应的就是Broker 端参数 log.index.interval.bytes 值,默认4KB,即4KB的消息建一条索引。
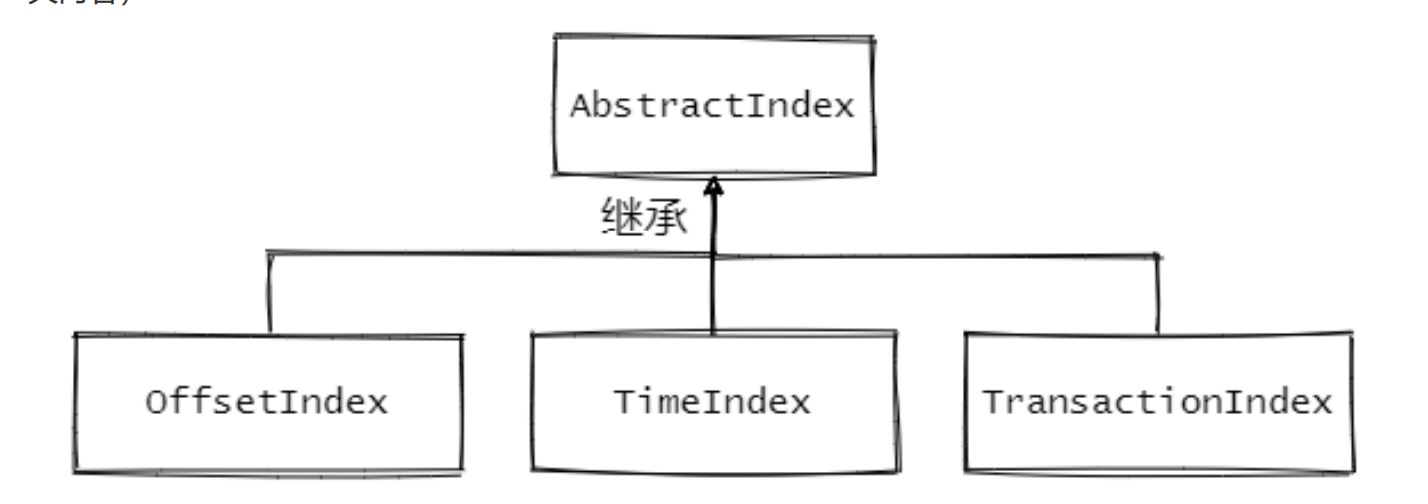
Kafka中有三大类索引:位移索引、时间戳索引和已中止事务索引。分别对应了.index .timeIndex
.txnindex文件。
与之相关的源码如下:
1、AbstractIndex.scala:抽象类,封装了所有索引的公共操作
2、OffsetIndex.scala:位移索引,保存了位移值和对应磁盘物理位置的关系
3、TimeIndex.scala:时间戳索引,保存了时间戳和对应位移值的关系
4、TransactionIndex.scala:事务索引,启用Kafka事务之后才会出现这个索引

成员变量里面还有个 entrySize 。这个变量其实是每个索引项的大小,每个索引项的大小是固定的。
entrySize
在 OffsetIndex 中是 override def entrySize = 8 ,8个字节。
在 TimeIndex 中是 override def entrySize = 12 ,12个字节。
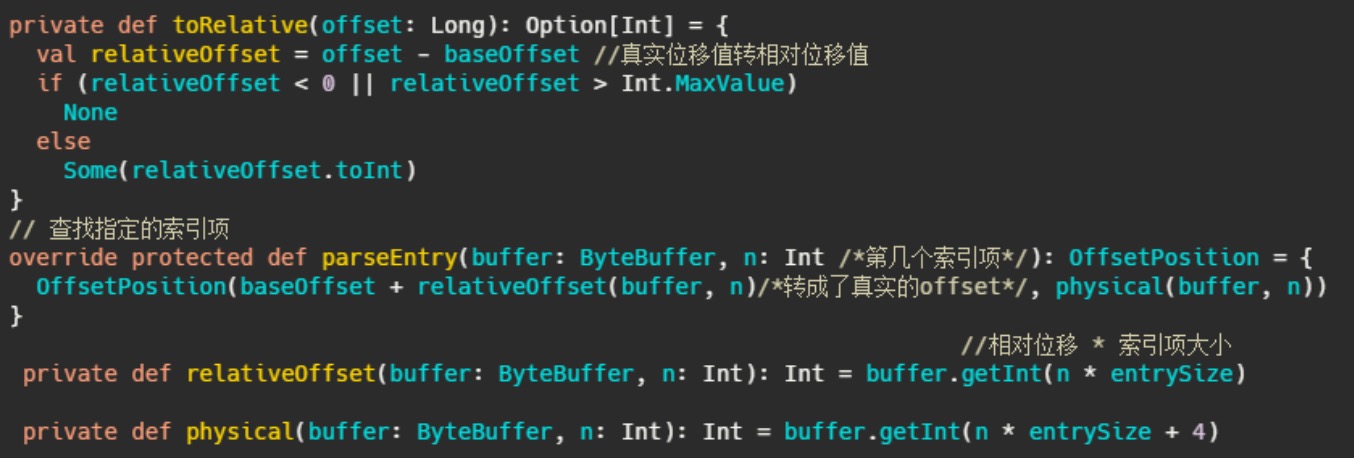
在 OffsetIndex 中,每个索引项存储了位移值和对应的磁盘物理位置,因此4+4=8,但是不对啊,磁盘物理位置是整型没问题,但是 AbstractIndex 的定义baseOffset来看,位移值是长整型,不是应该8个字节么
实际存储的位移值实际上是相对位移值,即真实位移值-baseOffset的值。
相对位移用整型存储够么?够,因为一个日志段文件大小的参数 log.segment.bytes 是整型,因此同
一个日志段对应的index文件上的位移值-baseOffset的值的差值肯定在整型的范围内
这样做有几个好处:
1、为了节省空间,一个索引项节省了4字节,想想那些日消息处理数万亿的公司
2、因为内存资源是很宝贵的,索引项越短,内存中能存储的索引项就越多,索引项多了直接命中的概率就高了。这其实和MySQL InnoDB 为何建议主键不宜过长一样。每个辅助索引都会存储主键的值,主键越长,每条索引项占用的内存就越大,缓存页一次从磁盘获取的索引数就越少,一次查询需要访问磁盘次数就可能变多。而磁盘访问我们都知道,很慢
_warmEntries
这个属性的用处就涉及到了索引的查找
kafka 无论是消息还是索引都是单调递增的,并且都是追加写入,因此数据都是有序的,在有序的集合中快速查询,就是二分查找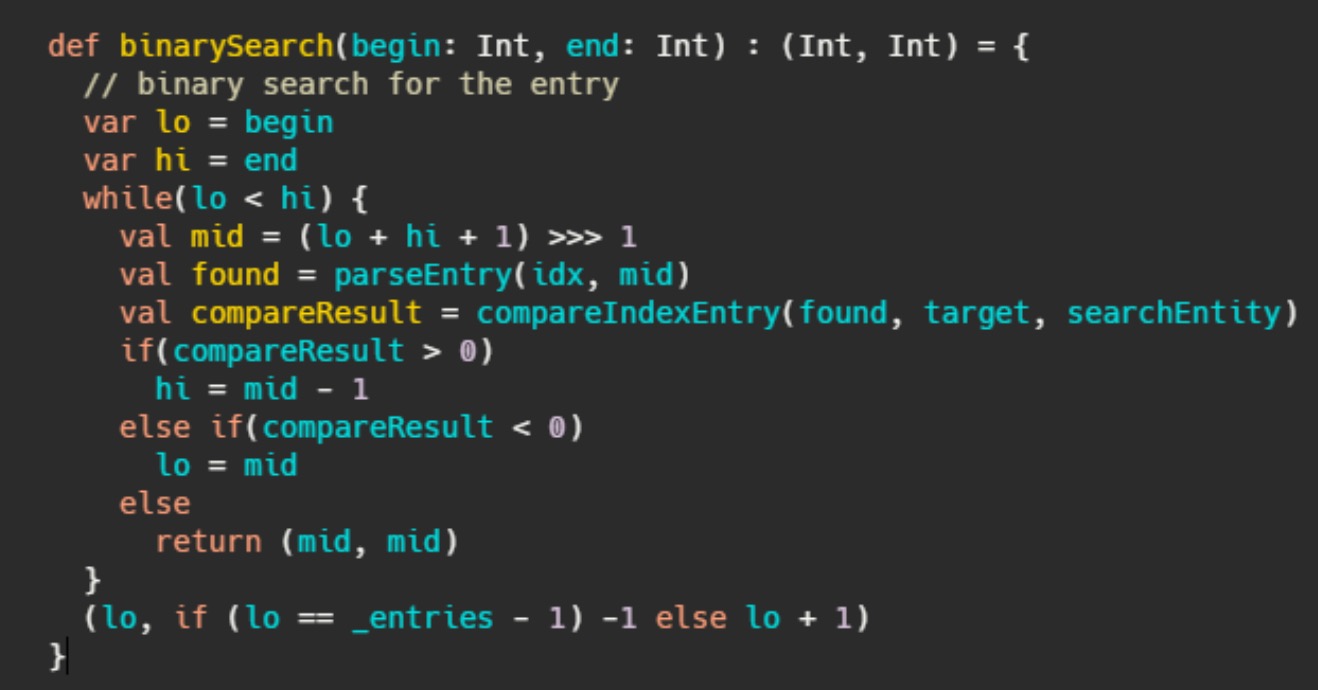
索引是在文件末尾追加的写入的,并且一般写入的数据立马就会被读取。所以数据的热点集中在尾部。并且操作系统基本上都是用页为单位缓存和管理内存的,内存又是有限的,因此会通过类LRU机制淘汰内存。
看起来LRU非常适合Kafka的场景,但是使用标准的二分查找会有缺页中断的情况,毕竟二分是跳着访问的
kafka官方注释:当我们查找索引的时候,标准的二分查找对缓存不友好,可能会造成不必要的缺页中断(线程被阻塞等待从磁盘加载没有被缓存到page cache 的数据)
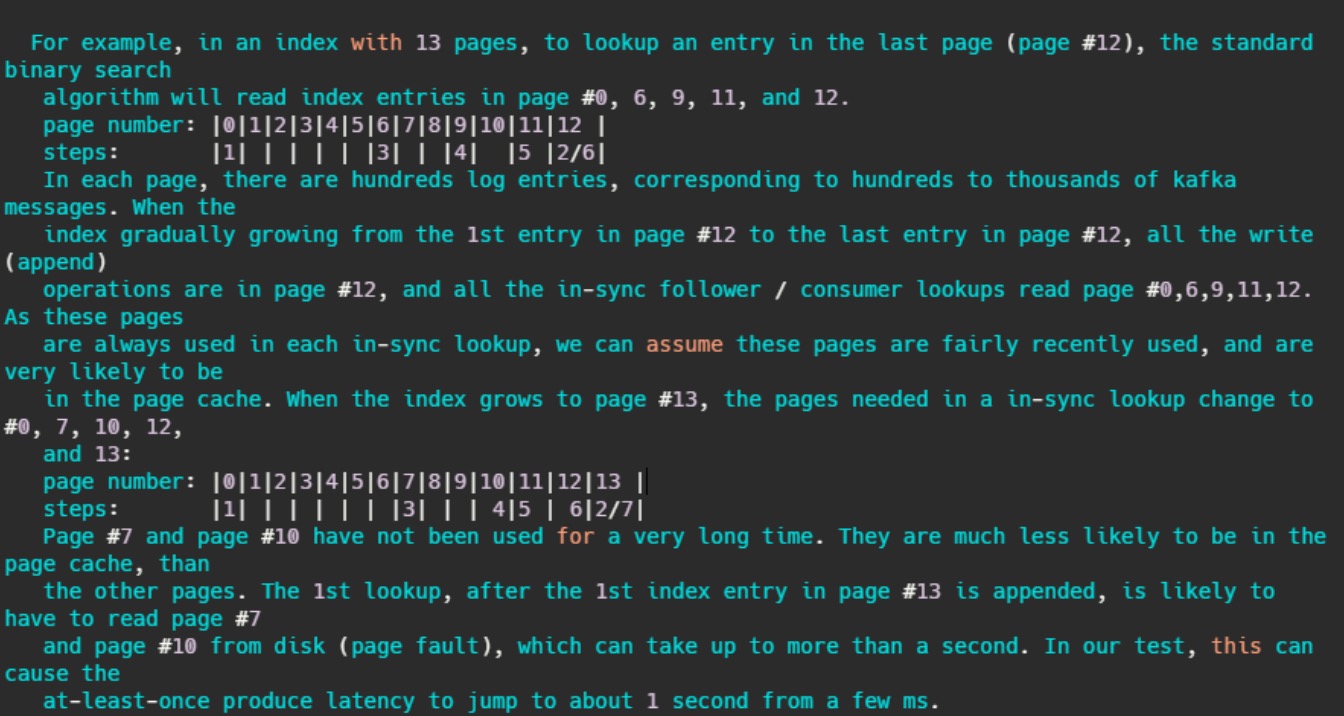
简单的来讲,假设某索引占page cache 13页,此时数据已经写到了12页。按照kafka访问的特性,此时访问的数据都在第12页,因此二分查找的特性,此时缓存页的访问顺序依次是0,6,9,11,12。因为频繁被访问,所以这几页一定存在page cache中。
当第12页不断被填充,满了之后会申请新页第13页保存索引项,而按照二分查找的特性,此时缓存页的访问顺序依次是:0,7,10,12。这7和10很久没被访问到了,很可能已经不再缓存中了,然后需要从磁盘上读取数据。注释说:在他们的测试中,这会导致至少会产生从几毫秒跳到1秒的延迟。
基于以上问题,Kafka使用了改进版的二分查找,改的不是二分查找的内部,而且把所有索引项分为热区和冷区这个改进可以让查询热数据部分时,遍历的Page永远是固定的,这样能避免缺页中断。
看到这里其实我想到了一致性hash,一致性hash相对于普通的hash不就是在node新增的时候缓存的
访问固定,或者只需要迁移少部分数据。
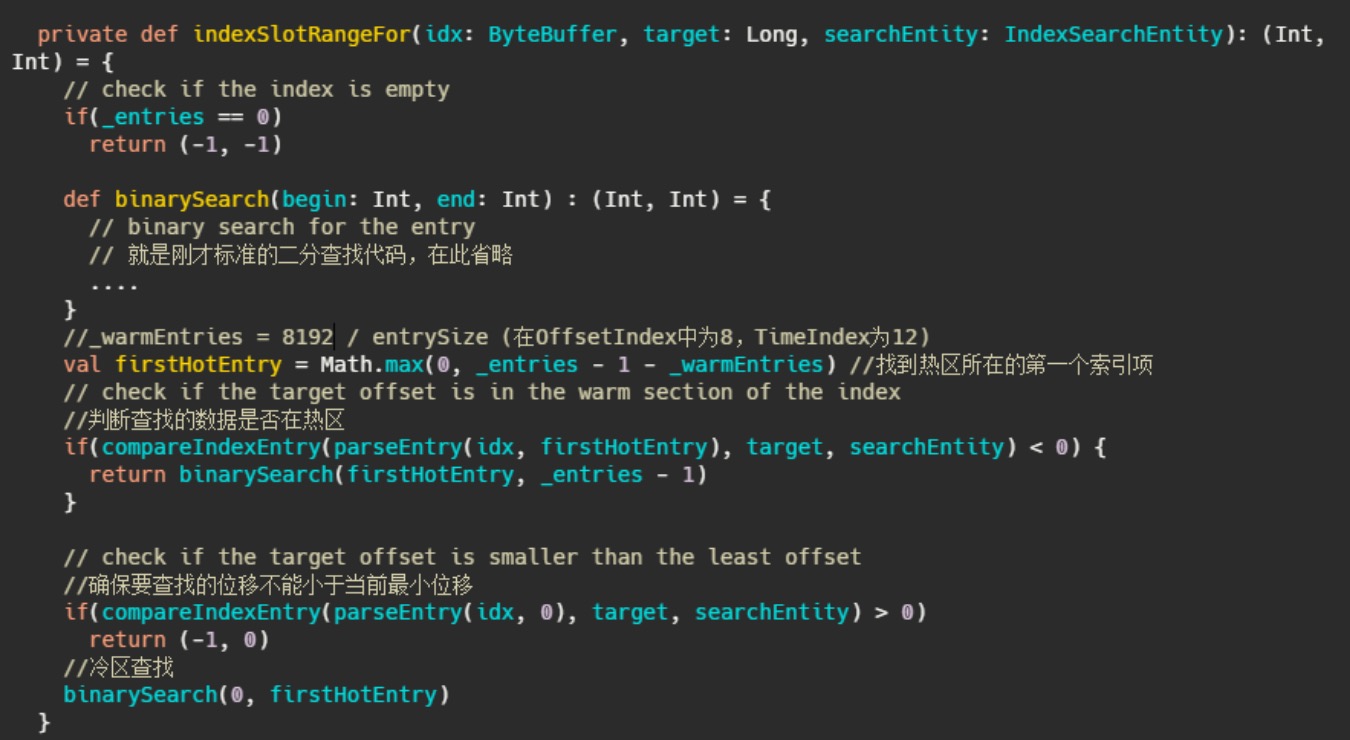
现在处理器一般缓存页大小是4096,那么8192可以保证页数小于等3,用于二分查
找的页面都能命中
联想到mysql的缓冲池管理
从上面这波冷热分区我又想到了MySQL的buffer pool管理。MySQL的将缓冲池分为了新生代和老年
代。默认是37分,即老年代占3,新生代占7。即看作一个链表的尾部30%为老年代,前面的70%为新生代。替换了标准的LRU淘汰机制。
MySQL的缓冲池分区是为了解决预读失效和缓存污染问题。
1、预读失效:因为会预读页,假设预读的页不会用到,那么就白白预读了,因此让预读的页插入的是老年代头部,淘汰也是从老年代尾部淘汰。不会影响新生代数据。
2、缓存污染:在类似like全表扫描的时候,会读取很多冷数据。并且有些查询频率其实很少,因此让这些数据仅仅存在老年代,然后快速淘汰才是正确的选择,MySQL为了解决这种问题,仅仅分代是不够的,还设置了一个时间窗口,默认是1s,即在老年代被再次访问并且存在超过1s,才会晋升到新生代,这样就不会污染新生代的热数据
Kafka日志段读写
Kafka存储结构
Kafka的Topic可以有多个分区,分区其实就是最小的读取和存储结构,即Consumer看似订
阅的是Topic,实则是从Topic下的某个分区获得消息,Producer也是发送消息也是如此。、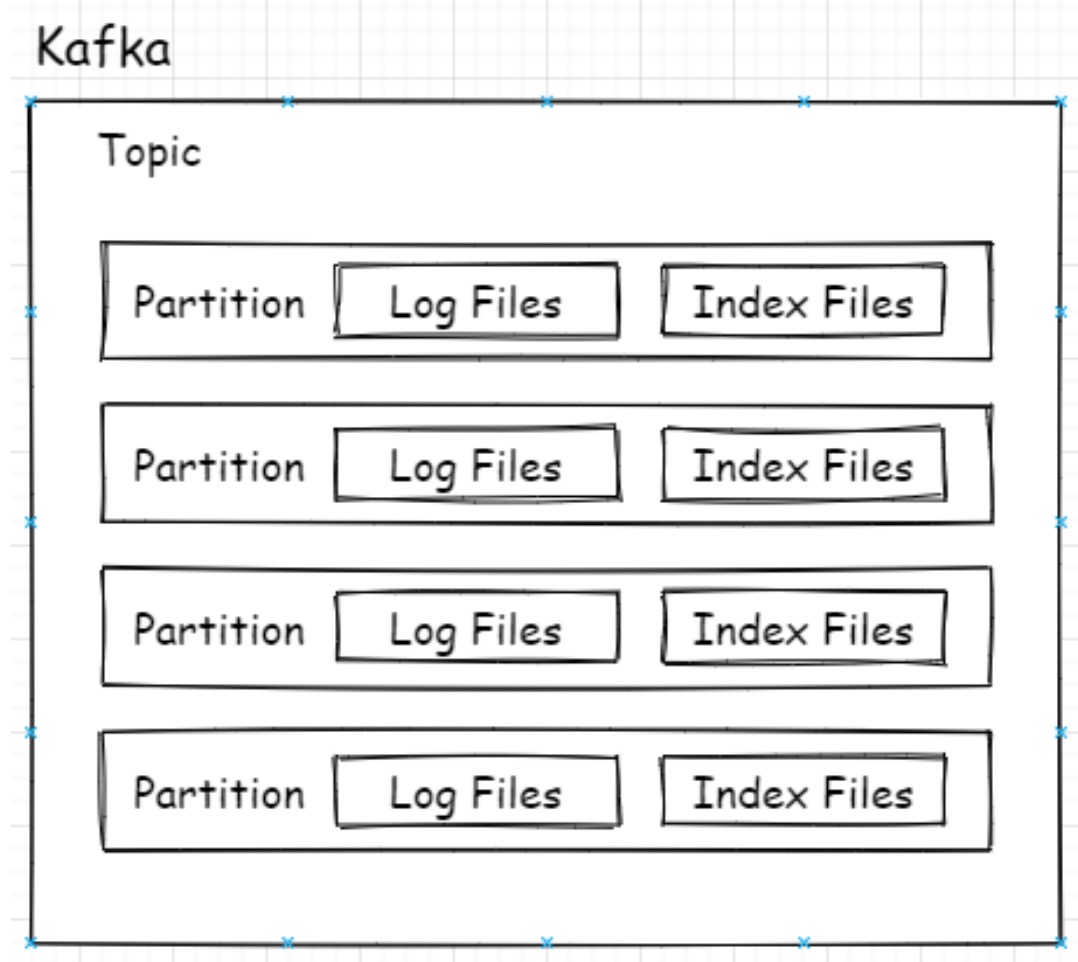
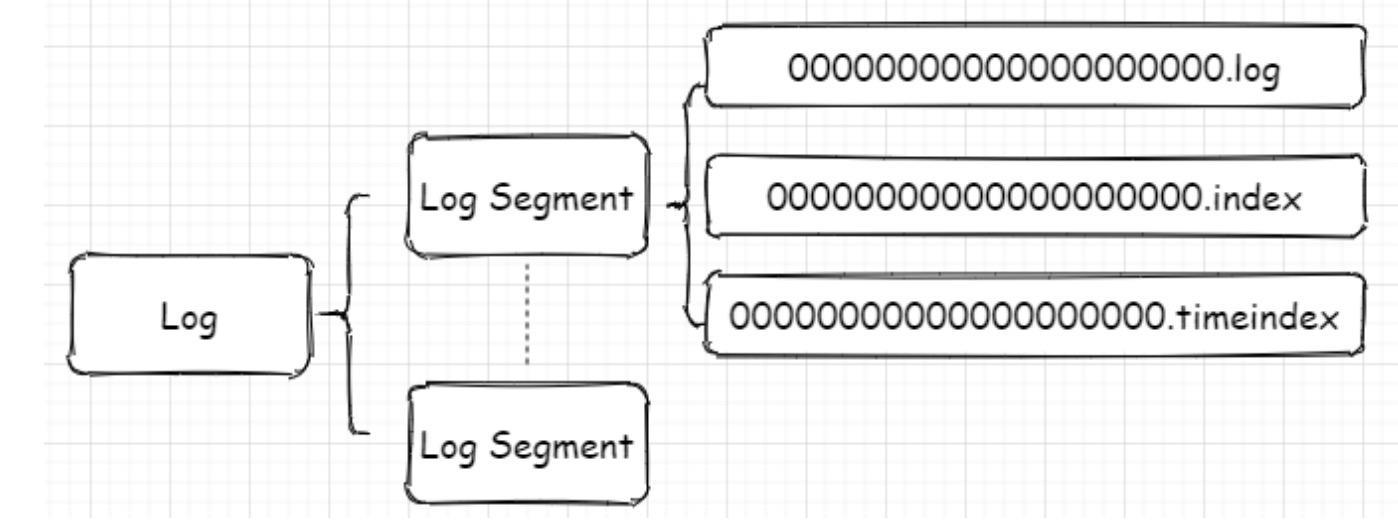
每个分区对应一个Log对象,在磁盘中就是一个子目录,子目录下面会有多组日志段即多Log
Segment,每组日志段包含:消息日志文件(以log结尾)、位移索引文件(以index结尾)、时间戳索引文件(以timeindex结尾)。其实还有其它后缀的文件
日志段的定义
日志的定义: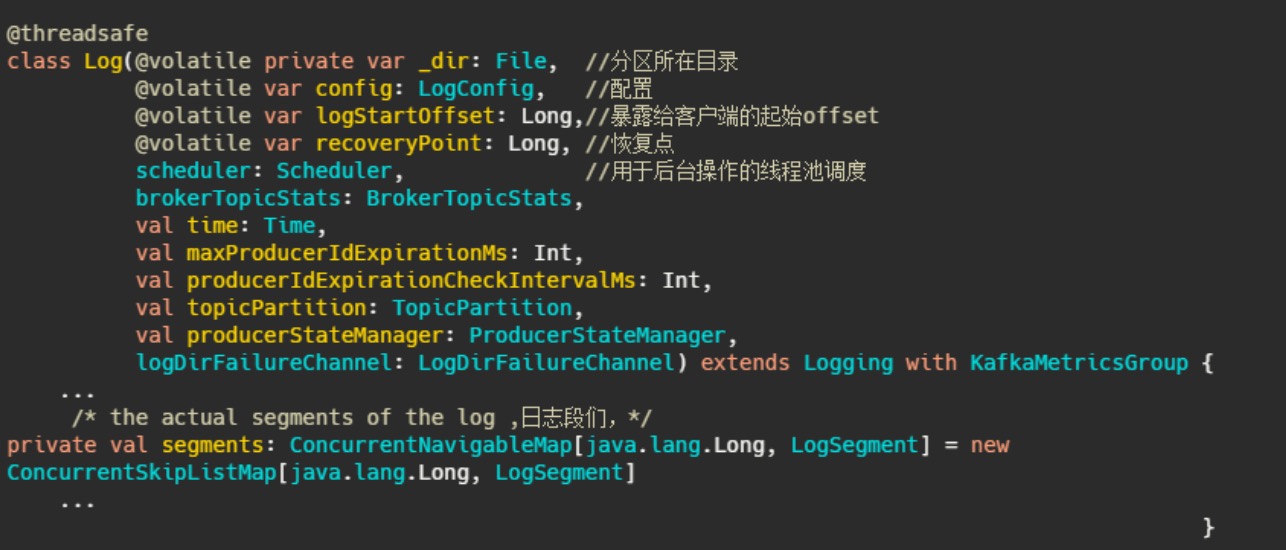
日志段的定义: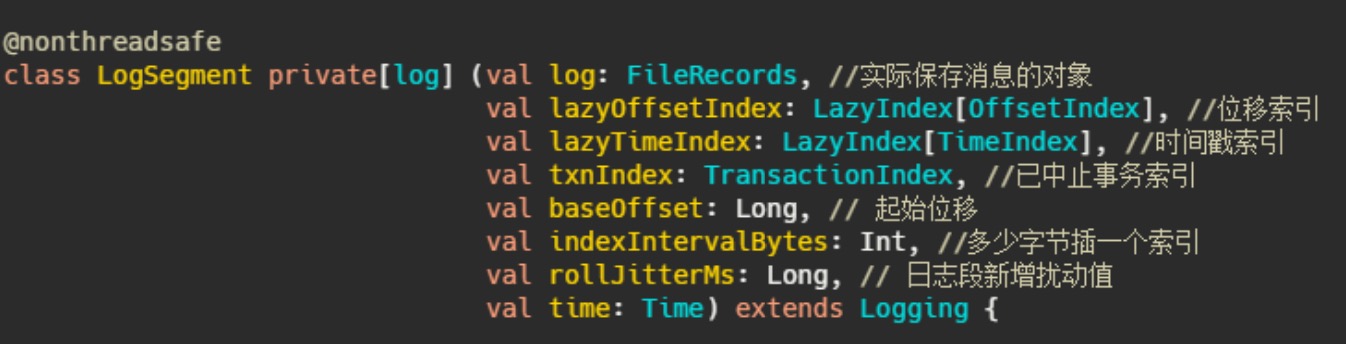
indexIntervalBytes 可以理解为插了多少消息之后再建一个索引,由此可以看出Kafka的索引其实是
稀疏索引,这样可以避免索引文件占用过多的内存,从而可以在内存中保存更多的索引。对应的就是Broker 端参数 log.index.interval.bytes 值,默认4KB。
实际的通过索引查找消息过程是先通过offset找到索引所在的文件,然后通过二分法找到离目标最近的索引,再顺序遍历消息文件找到目标文件。这波操作时间复杂度为 O(log2n)+O(m) ,n是索引文件里索引的个数,m为稀疏程度。
再说下 rollJitterMs ,这其实是个扰动值,对应的参数是 log.roll.jitter.ms ,这其实就要说到日志
段的切分了, log.segment.bytes ,这个参数控制着日志段文件的大小,默认是1G,即当文件存储超过1G之后就新起一个文件写入。这是以大小为维度的,还有一个参数是 log.segment.ms ,以时间为维度切分。
那配置了这个参数之后如果有很多很多分区,然后因为这个参数是全局的,因此同一时刻需要做很多文件的切分,这磁盘IO就顶不住了啊,因此需要设置个 rollJitterMs ,来岔开它们。
日志段写入
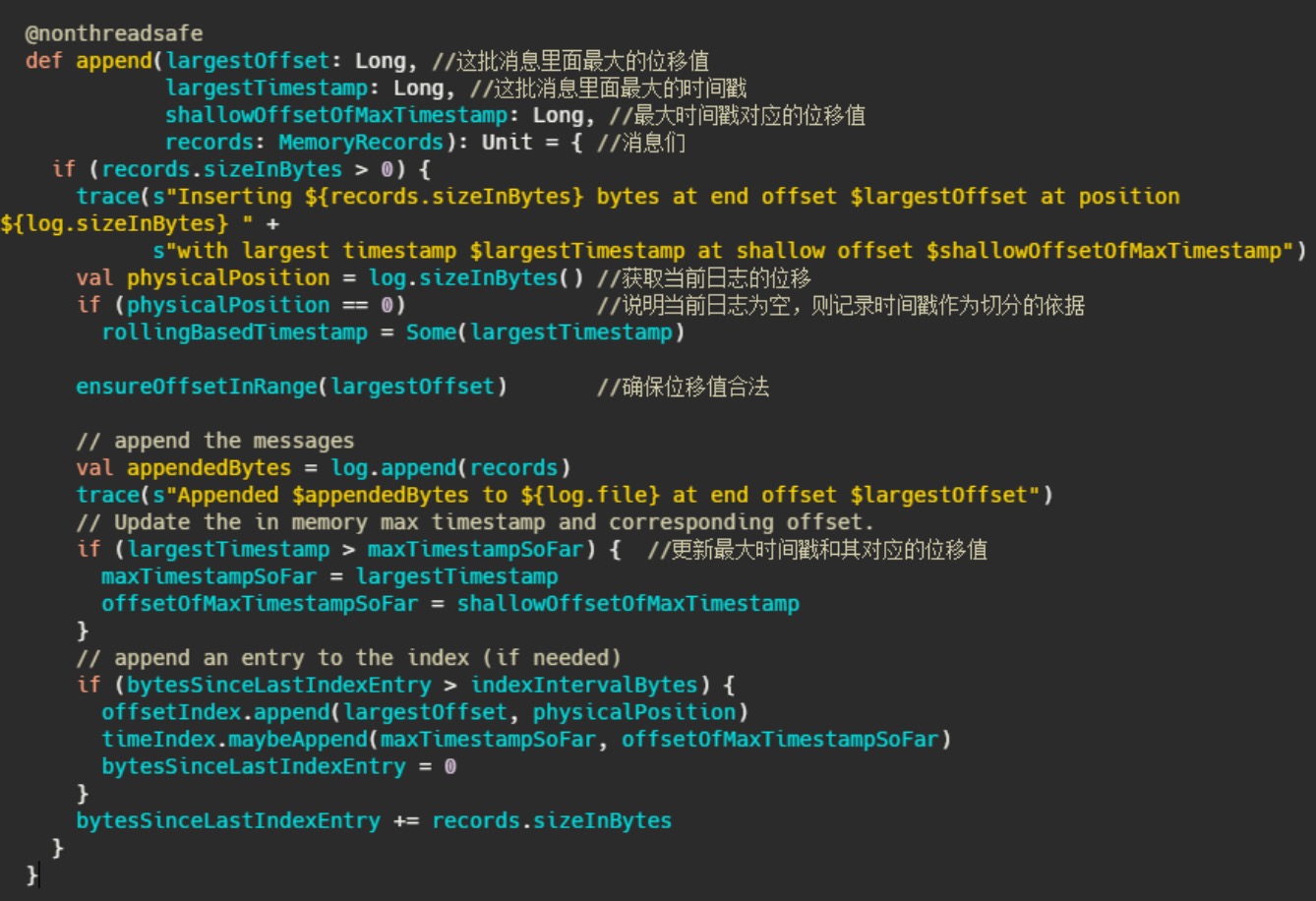
1、判断下当前日志段是否为空,空的话记录下时间,来作为之后日志段的切分依据
2、确保位移值合法,最终调用的是 AbstractIndex.toRelative(..) 方法,即使判断offset是否小于
0,是否大于int最大值。
3、append消息,实际上就是通过 FileChannel 将消息写入,当然只是写入内存中及页缓存,是否刷
盘看配置。
4、更新日志段最大时间戳和最大时间戳对应的位移值。这个时间戳其实用来作为定期删除日志的依据
5、更新索引项,如果需要的话 (bytesSinceLastIndexEntry > indexIntervalBytes)
流程图: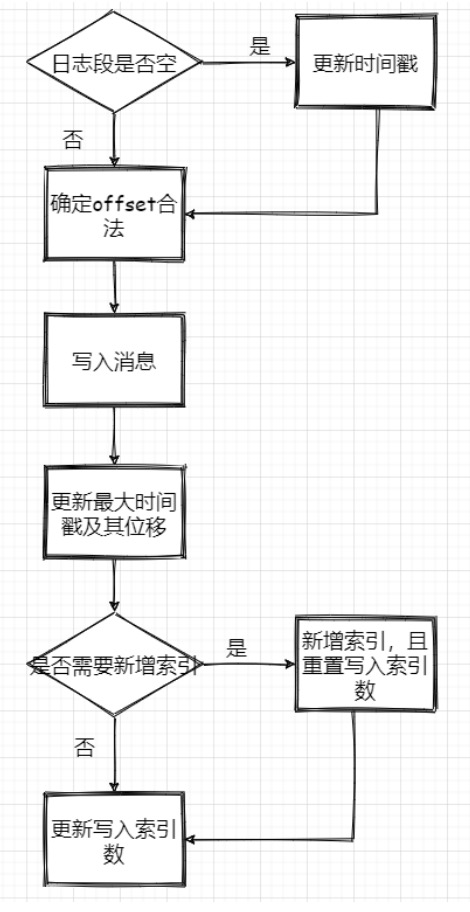
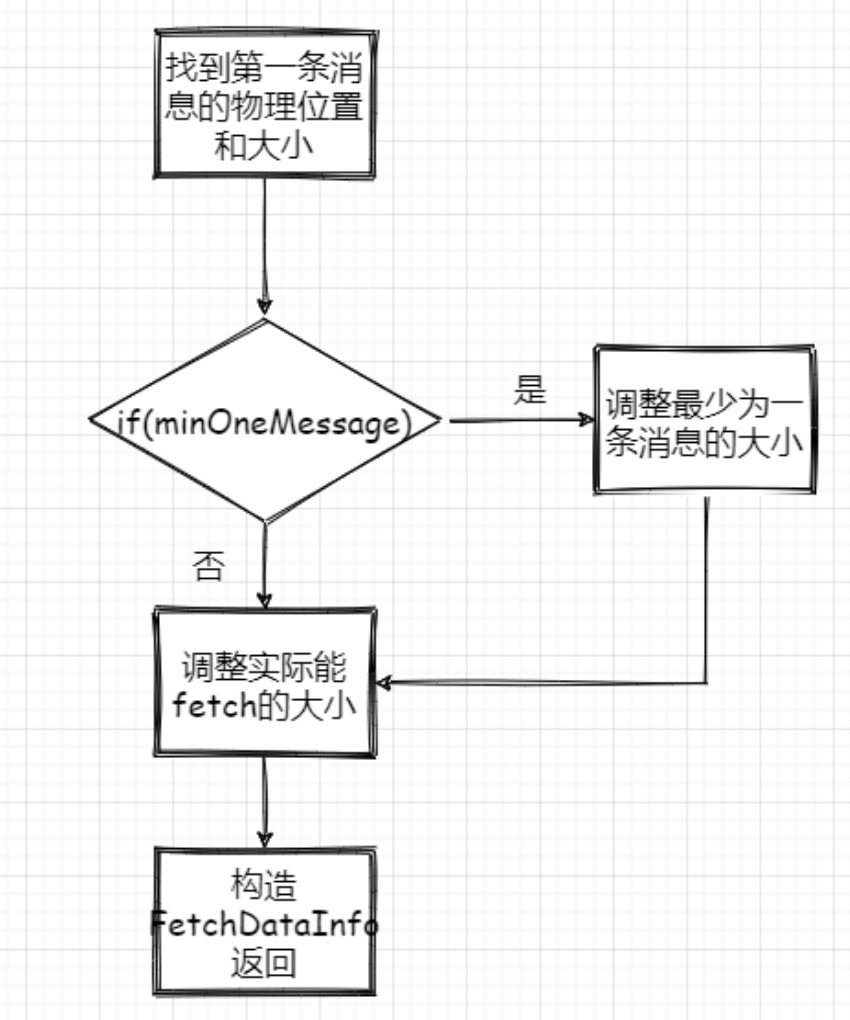
日志段读取
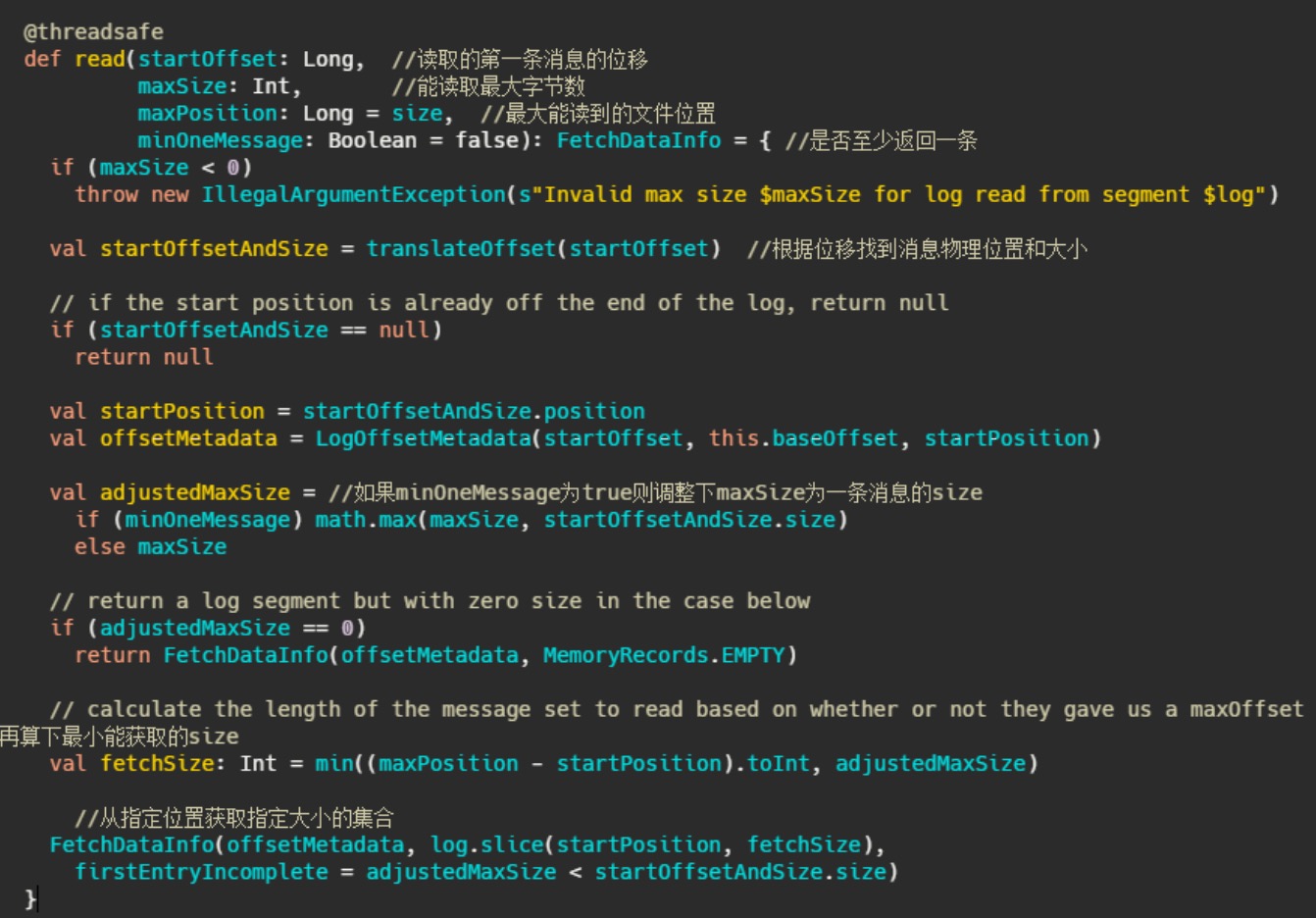
1、根据第一条消息的offset,通过 OffsetIndex 找到对应的消息所在的物理位置和大小。
2、获取 LogOffsetMetadata ,元数据包含消息的offset、消息所在segment的起始offset和物理位置
3、判断 minOneMessage 是否为 true ,若是则调整为必定返回一条消息大小,其实就是在单条消息大于maxSize 的情况下得以返回,防止消费者饿死
4、再计算最大的 fetchSize ,即(最大物理位移-此消息起始物理位移)和 adjustedMaxSize 的最小值(这波我不是很懂,因为以上一波操作 adjustedMaxSize 已经最小为一条消息的大小了)
5、调用 FileRecords 的 slice 方法从指定位置读取指定大小的消息集合,并且构造FetchDataInfo 返回
流程图: