GO的协程:goroutine
线程其实并不是真正运行的实体, 线程只是代表一个执行流和其状态.真正运行驱动流程往前的其实是 CPU. CPU 在时钟的驱动下, 根据PC寄存器从程序中取指令和操作数,从RAM中取数据,进行计算,处理,跳转,驱动执行流往前.CPU并不关注处理的是线程还是协程, 只需要设置 PC 寄存器, 设置栈指针等(这些称为上下文), 那么 CPU 就可以运行这个线程或者这个协程了
线程的运行, 其实是被运行.其阻塞, 其实是切换出调度队列, 不再去调度执行这个执行流. 其他执行流满足其条件, 便会把被移出调度队列的执行流重新放回调度队列
协程其实也是一个数据结构,记录了要运行什么函数,运行到哪里了,go在用户态实现调度,所以go要有代表协程这种执行流的结构体, 也要有保存和恢复上下文的函数, 运行队列.
调度相关数据结构
G
每个go func都代表一个g,无限制数量,代表一个用户代码的执行流
1 | struct G |
真正代表协程的是 runtime.g 结构体. 每个 go func 都会编译成 runtime.newproc 函数, 最终有一个 runtime.g 对象放入调度队列,参数会在 newproc 函数里拷贝到 stack 中, sched 用于保存协程切换时的 pc 位置和栈位置
切换时并不必陷入到操作系统内核中,所以保存过程很轻量。看一下结构体G中的Gobuf,其实只保存了当前栈指针,程序计数器,以及goroutine自身
1 | struct Gobuf |
M
runtime.m,代表真正的OS线程, 每个m都是对应到一条操作系统的物理线程,最大一万个,代表执行者,底层线程
1 | struct M |
M中还有一个MCache,是当前M的内存的缓存。M也和G一样有一个常驻寄存器变量,代表当前的M。同时存在多个M,表示同时存在多个物理线程。
结构体M中有两个G是需要关注一下的,一个是curg,代表结构体M当前绑定的结构体G。另一个是g0,是带有调度栈的goroutine,这是一个比较特殊的goroutine。普通的goroutine的栈是在堆上分配的可增长的栈,而g0的栈是M对应的线程的栈。所有调度相关的代码,会先切换到该goroutine的栈中再执行
P
runtime.p,默认为机器核数,通过GOMAXPROCS环境变量设置,表示执行所需要的资源
1 | struct P |
在P中有一个Grunnable的goroutine队列,这是一个P的局部队列。当P执行Go代码时,它会优先从自己的这个局部队列中取,这时可以不用加锁,提高了并发度。如果发现这个队列空了,则去其它P的队列中拿一半过来,这样实现工作流窃取的调度。这种情况下是需要给调用器加锁的。
局部队列也就是本地队列
一个 P 可以与多个 M 对应,但同一时刻,这个 P 只能和其中一个 M 发生绑定关系
sched
在proc.c文件中
1 | struct Sched { |
其中有M的idle队列,P的idle队列,以及一个全局的就绪的G队列。Sched结构体中的Lock是非常必须的,如果M或P等做一些非局部的操作,它们一般需要先锁住调度器。
调度
M,P,G,Sched
1.Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
2.M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
3.P全称是Processor,处理器,它的主要用途就是用来执行goroutine的,所以它也维护了一个goroutine队列,里面存储了所有需要它来执行的goroutine,这个P的角色可能有一点让人迷惑,一开始容易和M冲突,后面重点聊一下它们的关系。
4.G就是goroutine实现的核心结构了,G维护了goroutine需要的栈、程序计数器以及它所在的M等信息
类比 M:工人, G:砖, P:工具
M用P执行G(工人用工具搬砖)
G需要绑定M运行
M需要绑定P运行
多个M并不会同时处于执行状态,最多只有P的个数(GOMAXPROCS)
M:P:G=1:1:N
启动过程
从启动过程开始说起:
1.调度器初始化runtime·schedinit
PS:根据用户设置的GOMAXPROCS值来创建一批P,不管GOMAXPROCS设置为多大,最多也只能创建256个P,为闲置状态
放置在调度器结构(Sched)的pidle字段维护的链表中存储起来,后续使用
2.runtime·newproc创建出第一个goroutine,这个goroutine将执行的函数是runtime·main
PS:runtime·main函数,创建了一个新的内核线程M,不过这个线程是一个特殊线程,它在整个运行期专门负责做特定的事情——系统监控(sysmon)
3.这第一个goroutine,也就是主goroutine
4.runtime·mstart执行这个主goroutine
创建G
1.通过go关键字创建,对应到调度器的接口就是runtime·newproc,将G放入当前M的P中
创建M
1.runtime根据实际情况去创建,G太多了,M少,有空闲的P
1 | void newm(void (*fn)(void), P *p) |
PS:newm函数的核心行为就是调用clone系统调用创建一个内核线程,每个内核线程的开始执行位置都是runtime·mstart函数
创建P
1.runtime·schedinit创建一批P, 根据GOMAXPROCS设置,最多也只能创建256个P
调度:窃取调度算法 work stealing
M分配P
newm接口给新建的M分配了一个P
1 | } else if(m != &runtime·m0) { |
没有P,M是无法执行goroutine的,对应acquirep的动作是releasep,把M装配的P给载掉
schedule调度
分配好P之后就是取G执行,也就是上面的schedule方法,简化后的代码如下
1 | static void |
1.runqget方法,M从自己的P的G队列中取G运行,成功则运行,失败则自己的P的G队列是空的,gp=nil,与自己的队列都是无锁交互
2.自己的P的G队列是空的,findrunnable方法,从全局的G队列,取G,全局G队列也是空的话,从其他M的P的G队列,窃取一半的G运行,如果都没有G,则卸掉P,线程sleep状态
3.wakep,一个M,自己的P的G队列太长,执行不过来,发现有闲置的P,则用闲置的M或者创建新的M,继续执行
4.execute最后执行G
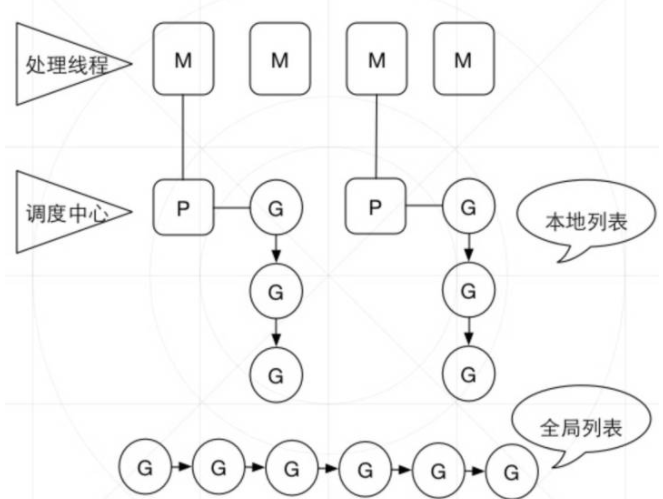
当M线程没有关联P来运行G时,就需要将G放入全局列表
阻塞点,切换调用,调度点
1.park goroutine: runtime·park函数。goroutine调用park后,这个goroutine就会被设置位waiting状态,放弃cpu,被park的goroutine处于waiting状态,并且这个goroutine不在P中,如果不对其调用runtime·ready,它是永远不会再被执行的
PS: channel操作,定时器中,网络poll等都有可能park goroutine
2.runtime·gosched:和park完全不同;gosched是将goroutine设置为runnable状态,然后放入到调度器全局等待队列
3.系统调用: 系统调用的时候执行entersyscall,退出后又执行exitsyscall函数。也只有封装了entersyscall的系统调用才有可能触发重新调度, 改变P的状态为syscall,通过sysmon线程监控抢占式调度,被抢P的M,只能把G放到全局队列,然后sleep
PS:sysmon线程:这个系统监控线程会扫描所有的P,发现一个P处于了syscall的状态,就知道这个P遇到了goroutine在做系统调用,于是系统监控线程就会创建一个新的M去把这个处于syscall的小车给抢过来
sysmon协程系统监控与抢占式调度
1.sysmon协程是在go runtime初始化之后,执行用户编码之前,不与任何P绑定,直接由一个M执行的内核线程
2.每10ms执行一次,初始20us,运行1ms翻倍,最终10ms,发生过抢占,则恢复到20us
稳定之后,会在循环之中执行以下工作
检查死锁
检查是否存在正在运行的线程
如果线程数量大于 0,说明当前程序不存在死锁;如果线程数小于 0,说明当前程序的状态不一致;如果线程数等于 0,我们需要进一步检查程序的运行状态
检查是否存在正在运行的 Goroutine
1.当存在 Goroutine 处于 Grunnable、Grunning 和 Gsyscall状态时,意味着程序发生了死锁
2.当所有的 Goroutine 都处于 Gidle、Gdead 和 Gcopystack 状态时,意味着主程序调用了 runtime.goexit
检查处理器上是否存在计时器
当运行时存在等待的 Goroutine 并且不存在正在运行的 Goroutine 时,我们会检查处理器中存在的计时器
如果处理器中存在等待的计时器,那么所有的 Goroutine 陷入休眠状态是合理的,不过如果不存在等待的计时器,运行时就会直接报错并退出程序
运行计时器
通过 runtime.nanotime 和 runtime.timeSleepUntil 获取当前时间和计时器下一次需要唤醒的时间,保证计时器时间不会有太大偏差,准确执行
轮询网络
系统监控还会在循环中轮询网络,检查是否有待执行的文件描述符
非阻塞地调用 runtime.netpoll 检查待执行的文件描述符并通过 runtime.injectglist 将所有处于就绪状态的 Goroutine 加入全局运行队列中
将所有 Goroutine 的状态从 Gwaiting 切换至 Grunnable 并加入全局运行队列等待运行
抢占处理器
循环中调用 runtime.retake函数抢占处于运行或者系统调用中的处理器,该函数会遍历运行时的全局处理器,每个处理器都存储了一个 runtime.sysmontick 结构体
1 | type sysmontick struct { |
retake函数会有两种抢占逻辑
1 | func retake(now int64) uint32 { |
1.当处理器处于 Prunning 或者 Psyscall 状态时,如果上一次触发调度的时间已经过去了 10ms,我们就会通过 runtime.preemptone 抢占当前处理器
2.当处理器处于 Psyscall 状态时,在满足以下两种情况下会调用 runtime.handoffp 让出处理器的使用权:
1.当处理器的运行队列不为空或者不存在空闲处理器时
2.当系统调用时间超过了 10ms 时
垃圾回收
系统监控还会决定是否需要触发强制垃圾回收,如果需要触发垃圾回收,我们会将用于垃圾回收的 Goroutine 加入全局队列,让调度器选择合适的处理器去执行
上下文切换保存
goroutine放弃cpu的时候,调用runtime·mcall函数,此函数也是汇编实现,主要将goroutine的栈地址和程序计数器保存到G结构的sched字段中,将相关寄存器的值给保存到内存中;恢复现场就是在goroutine重新获得cpu的时候,runtime·gogocall,这个函数主要在execute中调用,需要从内存把之前的寄存器信息全部放回到相应寄存器中去
goroutine与python yield
1.创建成本:Go 原生支持协程,通过 go func() 就可以创建一个 goroutine。Python 可以通过 gevent.spawn 来新建一个 coroutine,需要第三方库来支持。
2.Goroutine 之间的通信更简单,通过 channel call 即可实现,上下文切换透明(只有少部分需要自己注意 Gosched)。Python 需要 yield 来传递数据和切换上下文(通过一些库封装后对调用者来说也是透明的,比如:gevent/tornado)。
3.Python coroutine 只会使用一个线程,所以只能利用单核。Goroutine 可以被多个线程调度,可以利用多核