Life has a funny way of working out, just when you start to believe it never will
GO的基本数据结构:map
Posted onEdited onInGOWord count in article: 7.9kReading time ≈7 mins.
解析go语言,go的基本类型 map
基本数据结构
G基本结构如下,runtime/map.go go版本 v1.11
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// A header for a Go map. type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go. // Make sure this stays in sync with the compiler's definition. count int // # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
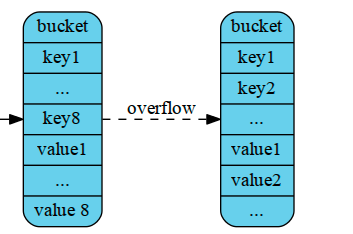
// A bucket for a Go map. type bmap struct { // tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead. tophash [bucketCnt]uint8 // Followed by bucketCnt keys and then bucketCnt values. // NOTE: packing all the keys together and then all the values together makes the // code a bit more complicated than alternating key/value/key/value/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8. // Followed by an overflow pointer. }
c := make(map[string]string) wg := sync.WaitGroup{} for i := 0; i < 10; i++ { wg.Add(1) go func(n int) { k, v := strconv.Itoa(n), strconv.Itoa(n) c[k] = v wg.Done() }(i) } wg.Wait() fmt.Println(c)
以上操作会触发协程安全错误
加锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
c := make(map[string]string) wg := sync.WaitGroup{} var lock sync.Mutex for i := 0; i < 10; i++ { wg.Add(1) go func(n int) { k, v := strconv.Itoa(n), strconv.Itoa(n) lock.Lock() c[k] = v lock.Unlock() wg.Done() }(i) } wg.Wait() fmt.Println(c)